Glossar mit Schlagwörtern als Tabs
Oberhalb der Ausgabe aller FAQ wird ein Glossar angezeigt, bei dem die Schlagwörter gleich groß dargestellt werden. Die FAQ sind nach Schlagwörter gruppiert. Das Glossar verlinkt auf die Schlagwörter.
Wird lediglich eine einzige FAQ gefunden, wird kein Glossar ausgegeben.
In der aktuellen Version des Plugins (Version 2.0.28 vom Oktober 2023) wird bei der Suche nach Veranstaltungen nur in den Datensatz der verantwortlichen Personen gesucht.
Daher werden Personen, die Einzeltermine durchführen, jedoch nicht als Verantwortliche eingetragen sind, auch nicht gefunden und somit deren Lehrveranstaltungen nicht angezeigt.
Eine Erweiterung des Plugins zur Suche und Darstellung von Lehrveranstaltungen für Dozenten, die nicht als Verantwortliche eingetragen sind, ist für eine spätere Version geplant.
Ja, Teile der Webstatistiken, die mit webalizer erstellt werden, können auch direkt abgerufen werden und danach mit einer geeigneten Software analysiert oder anders dargestellt werden.
Die folgenden Dateien liegen mit den entsprechenden Datumsformat (YYYY = Jahreszahl, MM = zweistellige Monatszahl, DD = zweistellige Tageszahl) jeweils in dem Statistik-Ordner des Webauftritts unter statistiken.rrze.fau.de/webauftritte/logs/Webauftritt/ .
Bitte beachten Sie, dass der Zugriff nur für Rechner aus den Netzen der Universität möglich ist.
Folgende Dateien stehen im Verzeichnis im CSV- bzw im XML-Format zur Verfügung:
- Useragents: agent_YYYYMM.tab
- Tagesdelta bei URL-Zugriffen: url_delta_YYYYMMDD.tab
- Referer: ref_YYYYMM.tab
- Suchbegriffe: search_YYYYMM.tab
- Usage: usage_YYYYMM.xml
- Site: site_YYYYMM.tab
- URL-Zugriffe: url_YYYYMM.tab
- Fehler: err_YYYYMM.tab
- Jahreszahlen: webalizer.hist
Nein, die E-Mailadressen werden von uns nicht manipuliert, sondern syntaktisch korrekt dargestellt.
Dies kann auch nicht verhindert oder umgangen werden.
Hintergründe:
Uns erhalten ab und zu Anfragen, ob man Mailadressen nicht automatisch so manipulieren könnte, damit Spam-Bots diese nicht erkennen.
Beispielsweise indem man das „@„-Zeichen durch die Zeichenfolge „[ at ]“ ersetzt.
Wir setzen solche Wünsche nicht um. Aus folgenden Gründen:
- Die Umsetzung derart würde zu einer Diskriminierung von Menschen führen, die aufgrund von den individuell verwendeten Geräten oder persönlichen Einschränkungen nicht in der Lage sind, dieserart manipulierter Adressen zu erkennen und zu nutzen. So führt eine oben genannte Umsetzung dazu, dass insbesondere Menschen, die auf Vorlesesoftware angewiesen sind und sich die Seiten vorlesen lassen müssen, die Inhalte nicht als solche korrekt vorgelesen bekommen. Diese Menschen sehen sich einer unnötigen Barriere gegenüber.
Das Recht auf Barrierefreiheit ist allerdings gesetzlich festgelegt und wir als Einrichtung des Öffentlichen Dienstes sind daran gehalten.
Der subjektive Vorteil des Empfängers eine E-Mail auf ein möglicherweise geringeres Spam-Aufkommen, rechtfertigt es nicht, andere Menschen durch den Aufbau von Barrieren zu diskriminieren.
Ausnahmetatbestände greifen nicht, da es mildere und effektivere Wege zur Vermeidung von Spam gibt (siehe unten). - Zudem ist der vermeintliche Schutz nicht fachlich haltbar und ein längst Mythos:
- Adressen der gängigen Forman Vorname.Nachname@Firmendomain.de werden vom Spamer längst en Block mittels zufallserstellter Namenslisten verwendet, ohne das hierzu ein Besuch einer Webseite notwendig ist.
- Die E-Mailadresse wird an vielen weiteren Stellen verwendet, auch über diese aktuelle Website hinaus. Spätestens nach Abgabe einer Visitenkarte mit Ihrer E-Mailadresse haben Sie keine Kontrolle mehr darüber, wie sie verbreitet wird.
- Selbst wenn Spam-Bots einer auf das Sammeln von E-Mailadressen spezialisierten Firma die Webseiten besuchen, erkennen diese alle gängigen Formen der Manipulation – auch solche, die uns hier noch gar nicht eingefallen sind. Denn diese Firmen verdienen ihr Geld damit, solche Adressen zu erkennen und zu verkaufen.
Es ist ein Trugschluss zu glauben, dass man durch eine simple automatische Textmanipulation des Zeichens @ in [ at ] von den professionellen Scannern nicht erkannt wird. Die automatische Umsetzung der Adresse in die eine Richtung ist technisch genauso trivial umsetzbar, wie es die umgekehrte Richtung ist.
Ebenso sind E-Mailadressen in der Umsetzung in Form von Bildern längst kein Schutz mehr. Entsprechende Funktionen der Mustererkennung sind seit mehr als einem Jahrzehnt gängiger Stand der Technik. Spätestens mit der Entwicklung neuer KI-Verfahren sind auch sehr komplexe Manipulationen, die aus der Kombination von Bildern, Texten und dynamisch erzeugten Content bestehen, kein Problem mehr für die automatische Erkennung durch Spam-Bots.Grundsätzlich kann festgehalten werden: Jegliche automatische und manuelle Text- und Bildmanipulation kann auch automatisch wieder rückgängig gemacht werden.
- Zur Vermeidung von Spam sind allein Spam-Erkennungs- und Filterverfahren auf der Empfängerseite legitim und sinnvoll. Hierzu finden Sie hier weitere Informationen auf derInformationsseite Anti-Spam des RRZE.
Die Zugriffe auf Webangebote, die am RRZE gehostet werden, sind aus dem Netz der Universität auf statistiken.rrze.fau.de abrufbar. Die Statistik wird mittels der Software webalizer erstellt und basiert auf die anonymisierten Zugriffe auf die Webserver.
In der Statistik werden unterschiedliche Begriffe verwendet:
- „Hits“, „Anfragen“, „Gesamtabrufe“
Die Begriffe „Hits“, „Anfragen“, „Gesamtabrufe“ und deren anderssprachige Formen stehen fuer die Summe der Anfragen auf einer Domain. Sie stehen aber nicht allein für die Summe der Anfragen fuer eine Seite. Genau gibt die Zahl an, wie oft Dateien innerhalb der Domain auf dem sich die Zahl bezieht, abgerufen wurden. Diese Dateien bestehen jedoch nicht nur aus den HTML-Dateien, sondern auch aus den in diesen referenzierten Bildern, Stylesheet-Dateien und Skript-Aufrufe.
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Hits“ in einer Statistik einer Domain kann nicht durch eine andere Abrufszahl überschritten werden.
- „Seiten“, „Seitenabrufe“, „Pageviews“, „Page Impressions“
Diese Begriffe beinhalten die Zahl der Abrufe auf Dokumentseiten _exklusive_ Referenzen auf Bilder, Stylesheet-Dateien oder Skript-Abrufen. Ausserdem werden zusätzlich nur Abrufe der Seiten gezählt, wenn diese vollstaendig vom Webserver geladen wurden. (Dies bedeutet, dass Seiten, die aus einem Proxy -also einem Zwischenspeicher für Webdokumente- geladen wurden, nicht mitgezählt wurden.)
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Pageviews“, bzw. der „Seiten“ ist jedoch nur 1. Für den Fall, daß ein Proxy die Seite gespeichert hatte bei dem der Browser des Benutzers die Seite abgerufen hat, ist die Zahl der Seitenabrufe sogar nur 0.
Die Zahl der „Pageviews“ kann niemals größer als die der „Hits“ sein.
- „Dateien“, „Files“
Diese Zahl gibt an, wieviele Dateien erfolgreich von der Domain geladen wurden. Dateien sind alle Dokumente auf der Webseite, inkl. Bilder und Skripten.
Der Unterschied zur Zahl der „Anfragen“/“Hits“ besteht darin, dass hier die Abrufe, bei denen der Seiteninhalt über einen Proxy geladen wurde, nicht mitgezählt werden. D.h.: ‚Zahl der „Hits“‚ – ‚Zahl der „Dateien“‚ = ‚Zahl der Seiten, die über einen Proxy abgerufen wurden.‘ Die Zahl der „Dateien“ ist meist nur für Interesse fuer den Webmaster, da diese Einfluss auf die Größe des Datentransfers hat.Die Zahl der „Dateien“ kann niemals größer als die der „Hits“ sein. Sie ist größer als die Zahl der „Seitenabrufe“
- „Besuche“, „Sessions“, „Sitzungen“
Diese Zahl beschreibt wieviele Besucher innerhalb eines festgelegten Zeitintervals Seiten, d.h. richtige Webseiten (die Grafiken etc nicht mitgezählt), vom Webserver erfolgreich abgerufen haben. Üblicherweise wird ein Wert von 90 Sekunden für den Zeitinterval benutzt.
Die Zahl der Seitenabrufe geteilt durch die Zahl der Besucher ergibt dabei die Zahl der Seiten, die ein Besucher auf der Seite betrachtet. (Portals und Suchmaschinen werden in der Regel eine kleinere Zahl haben, als inhaltlich bezogene Seiten, die nicht sofort auf externe Angebote verweisen.)
Kurz gesagt: Je größer der Wert „Seitenabrufe“/“Besuche“ ist, je laenger bleiben die Besucher auf der Seite.Die Zahl der „Besuche“ kann niemals größer als die der „Pageviews“ sein.
- „Rechner“, „Hosts“
Diese Zahl gibt an, wieviele verschiedene Rechner innerhalb eines Zeitintervalles „Seitenabrufe“ tätigten. (Bitte beachten Sie hierbei, dass Benutzer der großen Onlinedienste meist unter einem einzigen Rechner identifiziert werden.)
Interessant ist diese Zahl dadurch, dass sie zusammen mit der Zahl der „Besuche“ eine Abschätzung zuläßt, wie oft ein spezieller Besucher zu der Seite zurückkommt, d.h. wie interessant das auch über längere Zeiträume hinweg ist.Die Zahl der „Rechner“ kann niemals größer als die der „Besuche“ sein.
Die statistische Werte halten dabei folgende Reihenfolge ein:
#“Hits“ >= #“Dateien“ >= #“Seiten“ >= #“Besuche“ >= #“Rechner“
(wobei das Zeichen ‚#‘ sich auf die Zahl bezieht.)
Unabhaengig von diesen Zahlen wird in den meisten Statistiken auch noch die Zahl der übertragenen kBytes angegeben. Diese Zahl bezieht sich in der Regel auf den Datentransfer aller Dateien innerhalb des Zeitintervals.
Der Wert #“Dateien“ / #’kBytes‘ gibt dabei die durchschnittliche Dateigröße pro Datei an.
In dem Fall, wo eine Website mehreren Departments einer Fakultät untergeordnet ist, ist zu empfehlen als Aufpunkt die Fakultät zu nehmen.
Wenn die Website mehreren Departments oder Einrichtungen verschiedener Fakultäten untergeordnet ist, würde als Aufpunkt die Uni selbst zu nehmen.
Der Ziel der Orga Breadcrumb ist der, das ein Besucher einer Website eine Vorstellung bekommt, zu welcher Organisation die Website gehört.
Dies kann aber neben dem rein organisatorischen Aspekt durchaus inhaltlich auch anderes sein.
Zum Beispiel wenn die Stellen von einem Department kommen, aber die Inhalte und Arbeiten um die es geht, einer anderen Forschungsrichtung zugeordnet werden könnten.
Überlegen Sie in diesen Fällen daher, was aus Sicht Ihrer Besucher und im Rahmen der Öffentlichkeitsarbeit nützlicher ist und entscheiden Sie pragmatisch.
In der aktuellen Version des Plugins (Version 2.0.28 vom Oktober 2023) wird bei der Suche nach Veranstaltungen nur in den Datensatz der verantwortlichen Personen gesucht.
Daher werden Personen, die Einzeltermine durchführen, jedoch nicht als Verantwortliche eingetragen sind, auch nicht gefunden und somit deren Lehrveranstaltungen nicht angezeigt.
Eine Erweiterung des Plugins zur Suche und Darstellung von Lehrveranstaltungen für Dozenten, die nicht als Verantwortliche eingetragen sind, ist für eine spätere Version geplant.
Das Lectures-Plugin kann derzeit keine Daten aus vergangenen Semestern anzeigen, da das Campo-System diese Daten leider nicht bereit stellt.
Es werden nur Veranstaltungen, aus dem letzten, dem aktuellen und den anstehenden Semester gezeigt.
Da Abfragen nach personenbezogenen Daten stets nur in dem Maße gemacht werden, wie es unbedingt technisch notwendig ist (Prinzip der Datensparsamkeit), können bei der Suche nach der lecturer_id nur Personen gefunden werden, die eine der folgenden Personengruppen zugehören:
- Einrichtungsleiter
- Professoren und Professorinnen
- Juniorprofessoren und Juniorprofessorinnenv
- Wissenschaftliche Mitarbeiter und Mitarbeiterinnen
- Honorarprofessoren und Honorarprofessorinnen
- Privatdozenten und Privatdozentinnen
- Außerplanmäßige Professoren und Professorinnen
- Lehrbeauftragte
- Gastdozent und Gastdozentinnen
- Gastwissenschaftler und Gastwissenschaftlerinnen
Nein, die E-Mailadressen werden von uns nicht manipuliert, sondern syntaktisch korrekt dargestellt.
Dies kann auch nicht verhindert oder umgangen werden.
Hintergründe:
Uns erhalten ab und zu Anfragen, ob man Mailadressen nicht automatisch so manipulieren könnte, damit Spam-Bots diese nicht erkennen.
Beispielsweise indem man das „@„-Zeichen durch die Zeichenfolge „[ at ]“ ersetzt.
Wir setzen solche Wünsche nicht um. Aus folgenden Gründen:
- Die Umsetzung derart würde zu einer Diskriminierung von Menschen führen, die aufgrund von den individuell verwendeten Geräten oder persönlichen Einschränkungen nicht in der Lage sind, dieserart manipulierter Adressen zu erkennen und zu nutzen. So führt eine oben genannte Umsetzung dazu, dass insbesondere Menschen, die auf Vorlesesoftware angewiesen sind und sich die Seiten vorlesen lassen müssen, die Inhalte nicht als solche korrekt vorgelesen bekommen. Diese Menschen sehen sich einer unnötigen Barriere gegenüber.
Das Recht auf Barrierefreiheit ist allerdings gesetzlich festgelegt und wir als Einrichtung des Öffentlichen Dienstes sind daran gehalten.
Der subjektive Vorteil des Empfängers eine E-Mail auf ein möglicherweise geringeres Spam-Aufkommen, rechtfertigt es nicht, andere Menschen durch den Aufbau von Barrieren zu diskriminieren.
Ausnahmetatbestände greifen nicht, da es mildere und effektivere Wege zur Vermeidung von Spam gibt (siehe unten). - Zudem ist der vermeintliche Schutz nicht fachlich haltbar und ein längst Mythos:
- Adressen der gängigen Forman Vorname.Nachname@Firmendomain.de werden vom Spamer längst en Block mittels zufallserstellter Namenslisten verwendet, ohne das hierzu ein Besuch einer Webseite notwendig ist.
- Die E-Mailadresse wird an vielen weiteren Stellen verwendet, auch über diese aktuelle Website hinaus. Spätestens nach Abgabe einer Visitenkarte mit Ihrer E-Mailadresse haben Sie keine Kontrolle mehr darüber, wie sie verbreitet wird.
- Selbst wenn Spam-Bots einer auf das Sammeln von E-Mailadressen spezialisierten Firma die Webseiten besuchen, erkennen diese alle gängigen Formen der Manipulation – auch solche, die uns hier noch gar nicht eingefallen sind. Denn diese Firmen verdienen ihr Geld damit, solche Adressen zu erkennen und zu verkaufen.
Es ist ein Trugschluss zu glauben, dass man durch eine simple automatische Textmanipulation des Zeichens @ in [ at ] von den professionellen Scannern nicht erkannt wird. Die automatische Umsetzung der Adresse in die eine Richtung ist technisch genauso trivial umsetzbar, wie es die umgekehrte Richtung ist.
Ebenso sind E-Mailadressen in der Umsetzung in Form von Bildern längst kein Schutz mehr. Entsprechende Funktionen der Mustererkennung sind seit mehr als einem Jahrzehnt gängiger Stand der Technik. Spätestens mit der Entwicklung neuer KI-Verfahren sind auch sehr komplexe Manipulationen, die aus der Kombination von Bildern, Texten und dynamisch erzeugten Content bestehen, kein Problem mehr für die automatische Erkennung durch Spam-Bots.Grundsätzlich kann festgehalten werden: Jegliche automatische und manuelle Text- und Bildmanipulation kann auch automatisch wieder rückgängig gemacht werden.
- Zur Vermeidung von Spam sind allein Spam-Erkennungs- und Filterverfahren auf der Empfängerseite legitim und sinnvoll. Hierzu finden Sie hier weitere Informationen auf derInformationsseite Anti-Spam des RRZE.
Wenn Kalendertermine aus Exchange auf der Webseite angezeigt werden, wird hierzu der ICS-Feed von Exchange verwendet.
Der ICS-Feed zeigt standardmäßig jedoch nur die Termine an, welche drei Monate in der Zukunft liegen. Alles darüber hinaus nicht.
Wenn die eingetragenen Termine entsprechend in der Zukunft liegen, können sie daher auch auf der Webseite nicht angezeigt werden.
- Navigieren Sie Einstellungen > RRZE Lectures
- Im Abschnitt „Suchen nach FAU-Org-Nr.“ suchen Sie nach Ihrer FAU Organisations-Nummer.

Bitte prüfen Sie die Konfiguration des Plugins im Backend hinsichtlich der Nutzung der eigenen FAUorg Nummer.
Ab der Version 2.0.28 wird in den Einstellungen festgelegt, ob die Suche nach Lehrveranstaltungen stets ergänzt wird um eine Filterung nach einer FAUorg Nummer, oder ob diese nur optional hinzukommt.
Wenn Sie beispielsweise gezielt nach Veranstaltungen einer Person suchen, die einer anderen Organisationsnummer zugehörig ist, in den EInstellungen aber gleichzeit angegeben wurde, nur solche Veranstaltungen zu finden, die einer anderen FAUorg Nummer zugewiesen sind, dann kann es keine Treffer geben.
Ändern Sie daher im Backend unter Einstellungen -> RRZE Lectures die Einstellung unter FAUorg Nummer verwenden ab auf die Option Füge die FAUorg zur Suche nach Veranstaltungen nur dann hinzu, wenn alle anderen notwendigen Mindestangaben fehlen.
Wenn Kalendertermine aus Exchange auf der Webseite angezeigt werden, wird hierzu der ICS-Feed von Exchange verwendet.
Der ICS-Feed zeigt standardmäßig jedoch nur die Termine an, welche drei Monate in der Zukunft liegen. Alles darüber hinaus nicht.
Wenn die eingetragenen Termine entsprechend in der Zukunft liegen, können sie daher auch auf der Webseite nicht angezeigt werden.
Zur Verifikation der Website als Property in den Google Webmaster Tools wird die Methode über den HTML-Tag ausgewählt. Google erstellt dann auf der Einrichtungsseite eine HTML-Anweisung. Von dieser Anweisung kopiert man den Bestandteil, der im Attribut „content“ angegeben ist.
Bei einer Website, die eines der FAU Themes nutzt, finden Sie im Customizer unter „Erweitert“ >> Metadaten und Inhalte ein Eingabefeld, in dem Sie diesen Content einfügen.
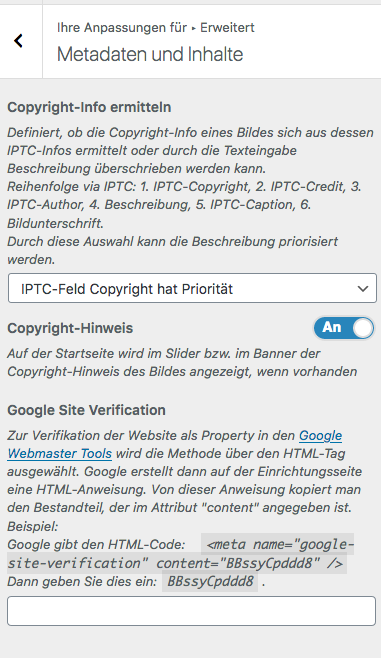
Nachdem Sie dies getan und gespeichert haben, lassen Sie Google die Website prüfen.
Google wird damit erkennen, dass Sie die Berechtigungen an der Website haben und Ihnen die Website zuordnen.
Die Zugriffe auf Webangebote, die am RRZE gehostet werden, sind aus dem Netz der Universität auf statistiken.rrze.fau.de abrufbar. Die Statistik wird mittels der Software webalizer erstellt und basiert auf die anonymisierten Zugriffe auf die Webserver.
In der Statistik werden unterschiedliche Begriffe verwendet:
- „Hits“, „Anfragen“, „Gesamtabrufe“
Die Begriffe „Hits“, „Anfragen“, „Gesamtabrufe“ und deren anderssprachige Formen stehen fuer die Summe der Anfragen auf einer Domain. Sie stehen aber nicht allein für die Summe der Anfragen fuer eine Seite. Genau gibt die Zahl an, wie oft Dateien innerhalb der Domain auf dem sich die Zahl bezieht, abgerufen wurden. Diese Dateien bestehen jedoch nicht nur aus den HTML-Dateien, sondern auch aus den in diesen referenzierten Bildern, Stylesheet-Dateien und Skript-Aufrufe.
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Hits“ in einer Statistik einer Domain kann nicht durch eine andere Abrufszahl überschritten werden.
- „Seiten“, „Seitenabrufe“, „Pageviews“, „Page Impressions“
Diese Begriffe beinhalten die Zahl der Abrufe auf Dokumentseiten _exklusive_ Referenzen auf Bilder, Stylesheet-Dateien oder Skript-Abrufen. Ausserdem werden zusätzlich nur Abrufe der Seiten gezählt, wenn diese vollstaendig vom Webserver geladen wurden. (Dies bedeutet, dass Seiten, die aus einem Proxy -also einem Zwischenspeicher für Webdokumente- geladen wurden, nicht mitgezählt wurden.)
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Pageviews“, bzw. der „Seiten“ ist jedoch nur 1. Für den Fall, daß ein Proxy die Seite gespeichert hatte bei dem der Browser des Benutzers die Seite abgerufen hat, ist die Zahl der Seitenabrufe sogar nur 0.
Die Zahl der „Pageviews“ kann niemals größer als die der „Hits“ sein.
- „Dateien“, „Files“
Diese Zahl gibt an, wieviele Dateien erfolgreich von der Domain geladen wurden. Dateien sind alle Dokumente auf der Webseite, inkl. Bilder und Skripten.
Der Unterschied zur Zahl der „Anfragen“/“Hits“ besteht darin, dass hier die Abrufe, bei denen der Seiteninhalt über einen Proxy geladen wurde, nicht mitgezählt werden. D.h.: ‚Zahl der „Hits“‚ – ‚Zahl der „Dateien“‚ = ‚Zahl der Seiten, die über einen Proxy abgerufen wurden.‘ Die Zahl der „Dateien“ ist meist nur für Interesse fuer den Webmaster, da diese Einfluss auf die Größe des Datentransfers hat.Die Zahl der „Dateien“ kann niemals größer als die der „Hits“ sein. Sie ist größer als die Zahl der „Seitenabrufe“
- „Besuche“, „Sessions“, „Sitzungen“
Diese Zahl beschreibt wieviele Besucher innerhalb eines festgelegten Zeitintervals Seiten, d.h. richtige Webseiten (die Grafiken etc nicht mitgezählt), vom Webserver erfolgreich abgerufen haben. Üblicherweise wird ein Wert von 90 Sekunden für den Zeitinterval benutzt.
Die Zahl der Seitenabrufe geteilt durch die Zahl der Besucher ergibt dabei die Zahl der Seiten, die ein Besucher auf der Seite betrachtet. (Portals und Suchmaschinen werden in der Regel eine kleinere Zahl haben, als inhaltlich bezogene Seiten, die nicht sofort auf externe Angebote verweisen.)
Kurz gesagt: Je größer der Wert „Seitenabrufe“/“Besuche“ ist, je laenger bleiben die Besucher auf der Seite.Die Zahl der „Besuche“ kann niemals größer als die der „Pageviews“ sein.
- „Rechner“, „Hosts“
Diese Zahl gibt an, wieviele verschiedene Rechner innerhalb eines Zeitintervalles „Seitenabrufe“ tätigten. (Bitte beachten Sie hierbei, dass Benutzer der großen Onlinedienste meist unter einem einzigen Rechner identifiziert werden.)
Interessant ist diese Zahl dadurch, dass sie zusammen mit der Zahl der „Besuche“ eine Abschätzung zuläßt, wie oft ein spezieller Besucher zu der Seite zurückkommt, d.h. wie interessant das auch über längere Zeiträume hinweg ist.Die Zahl der „Rechner“ kann niemals größer als die der „Besuche“ sein.
Die statistische Werte halten dabei folgende Reihenfolge ein:
#“Hits“ >= #“Dateien“ >= #“Seiten“ >= #“Besuche“ >= #“Rechner“
(wobei das Zeichen ‚#‘ sich auf die Zahl bezieht.)
Unabhaengig von diesen Zahlen wird in den meisten Statistiken auch noch die Zahl der übertragenen kBytes angegeben. Diese Zahl bezieht sich in der Regel auf den Datentransfer aller Dateien innerhalb des Zeitintervals.
Der Wert #“Dateien“ / #’kBytes‘ gibt dabei die durchschnittliche Dateigröße pro Datei an.
Ja, Teile der Webstatistiken, die mit webalizer erstellt werden, können auch direkt abgerufen werden und danach mit einer geeigneten Software analysiert oder anders dargestellt werden.
Die folgenden Dateien liegen mit den entsprechenden Datumsformat (YYYY = Jahreszahl, MM = zweistellige Monatszahl, DD = zweistellige Tageszahl) jeweils in dem Statistik-Ordner des Webauftritts unter statistiken.rrze.fau.de/webauftritte/logs/Webauftritt/ .
Bitte beachten Sie, dass der Zugriff nur für Rechner aus den Netzen der Universität möglich ist.
Folgende Dateien stehen im Verzeichnis im CSV- bzw im XML-Format zur Verfügung:
- Useragents: agent_YYYYMM.tab
- Tagesdelta bei URL-Zugriffen: url_delta_YYYYMMDD.tab
- Referer: ref_YYYYMM.tab
- Suchbegriffe: search_YYYYMM.tab
- Usage: usage_YYYYMM.xml
- Site: site_YYYYMM.tab
- URL-Zugriffe: url_YYYYMM.tab
- Fehler: err_YYYYMM.tab
- Jahreszahlen: webalizer.hist
Wenn Kalendertermine aus Exchange auf der Webseite angezeigt werden, wird hierzu der ICS-Feed von Exchange verwendet.
Der ICS-Feed zeigt standardmäßig jedoch nur die Termine an, welche drei Monate in der Zukunft liegen. Alles darüber hinaus nicht.
Wenn die eingetragenen Termine entsprechend in der Zukunft liegen, können sie daher auch auf der Webseite nicht angezeigt werden.
Die Zugriffe auf Webangebote, die am RRZE gehostet werden, sind aus dem Netz der Universität auf statistiken.rrze.fau.de abrufbar. Die Statistik wird mittels der Software webalizer erstellt und basiert auf die anonymisierten Zugriffe auf die Webserver.
In der Statistik werden unterschiedliche Begriffe verwendet:
- „Hits“, „Anfragen“, „Gesamtabrufe“
Die Begriffe „Hits“, „Anfragen“, „Gesamtabrufe“ und deren anderssprachige Formen stehen fuer die Summe der Anfragen auf einer Domain. Sie stehen aber nicht allein für die Summe der Anfragen fuer eine Seite. Genau gibt die Zahl an, wie oft Dateien innerhalb der Domain auf dem sich die Zahl bezieht, abgerufen wurden. Diese Dateien bestehen jedoch nicht nur aus den HTML-Dateien, sondern auch aus den in diesen referenzierten Bildern, Stylesheet-Dateien und Skript-Aufrufe.
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Hits“ in einer Statistik einer Domain kann nicht durch eine andere Abrufszahl überschritten werden.
- „Seiten“, „Seitenabrufe“, „Pageviews“, „Page Impressions“
Diese Begriffe beinhalten die Zahl der Abrufe auf Dokumentseiten _exklusive_ Referenzen auf Bilder, Stylesheet-Dateien oder Skript-Abrufen. Ausserdem werden zusätzlich nur Abrufe der Seiten gezählt, wenn diese vollstaendig vom Webserver geladen wurden. (Dies bedeutet, dass Seiten, die aus einem Proxy -also einem Zwischenspeicher für Webdokumente- geladen wurden, nicht mitgezählt wurden.)
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Pageviews“, bzw. der „Seiten“ ist jedoch nur 1. Für den Fall, daß ein Proxy die Seite gespeichert hatte bei dem der Browser des Benutzers die Seite abgerufen hat, ist die Zahl der Seitenabrufe sogar nur 0.
Die Zahl der „Pageviews“ kann niemals größer als die der „Hits“ sein.
- „Dateien“, „Files“
Diese Zahl gibt an, wieviele Dateien erfolgreich von der Domain geladen wurden. Dateien sind alle Dokumente auf der Webseite, inkl. Bilder und Skripten.
Der Unterschied zur Zahl der „Anfragen“/“Hits“ besteht darin, dass hier die Abrufe, bei denen der Seiteninhalt über einen Proxy geladen wurde, nicht mitgezählt werden. D.h.: ‚Zahl der „Hits“‚ – ‚Zahl der „Dateien“‚ = ‚Zahl der Seiten, die über einen Proxy abgerufen wurden.‘ Die Zahl der „Dateien“ ist meist nur für Interesse fuer den Webmaster, da diese Einfluss auf die Größe des Datentransfers hat.Die Zahl der „Dateien“ kann niemals größer als die der „Hits“ sein. Sie ist größer als die Zahl der „Seitenabrufe“
- „Besuche“, „Sessions“, „Sitzungen“
Diese Zahl beschreibt wieviele Besucher innerhalb eines festgelegten Zeitintervals Seiten, d.h. richtige Webseiten (die Grafiken etc nicht mitgezählt), vom Webserver erfolgreich abgerufen haben. Üblicherweise wird ein Wert von 90 Sekunden für den Zeitinterval benutzt.
Die Zahl der Seitenabrufe geteilt durch die Zahl der Besucher ergibt dabei die Zahl der Seiten, die ein Besucher auf der Seite betrachtet. (Portals und Suchmaschinen werden in der Regel eine kleinere Zahl haben, als inhaltlich bezogene Seiten, die nicht sofort auf externe Angebote verweisen.)
Kurz gesagt: Je größer der Wert „Seitenabrufe“/“Besuche“ ist, je laenger bleiben die Besucher auf der Seite.Die Zahl der „Besuche“ kann niemals größer als die der „Pageviews“ sein.
- „Rechner“, „Hosts“
Diese Zahl gibt an, wieviele verschiedene Rechner innerhalb eines Zeitintervalles „Seitenabrufe“ tätigten. (Bitte beachten Sie hierbei, dass Benutzer der großen Onlinedienste meist unter einem einzigen Rechner identifiziert werden.)
Interessant ist diese Zahl dadurch, dass sie zusammen mit der Zahl der „Besuche“ eine Abschätzung zuläßt, wie oft ein spezieller Besucher zu der Seite zurückkommt, d.h. wie interessant das auch über längere Zeiträume hinweg ist.Die Zahl der „Rechner“ kann niemals größer als die der „Besuche“ sein.
Die statistische Werte halten dabei folgende Reihenfolge ein:
#“Hits“ >= #“Dateien“ >= #“Seiten“ >= #“Besuche“ >= #“Rechner“
(wobei das Zeichen ‚#‘ sich auf die Zahl bezieht.)
Unabhaengig von diesen Zahlen wird in den meisten Statistiken auch noch die Zahl der übertragenen kBytes angegeben. Diese Zahl bezieht sich in der Regel auf den Datentransfer aller Dateien innerhalb des Zeitintervals.
Der Wert #“Dateien“ / #’kBytes‘ gibt dabei die durchschnittliche Dateigröße pro Datei an.
Wenn Kalendertermine aus Exchange auf der Webseite angezeigt werden, wird hierzu der ICS-Feed von Exchange verwendet.
Der ICS-Feed zeigt standardmäßig jedoch nur die Termine an, welche drei Monate in der Zukunft liegen. Alles darüber hinaus nicht.
Wenn die eingetragenen Termine entsprechend in der Zukunft liegen, können sie daher auch auf der Webseite nicht angezeigt werden.
Bitte prüfen Sie die Konfiguration des Plugins im Backend hinsichtlich der Nutzung der eigenen FAUorg Nummer.
Ab der Version 2.0.28 wird in den Einstellungen festgelegt, ob die Suche nach Lehrveranstaltungen stets ergänzt wird um eine Filterung nach einer FAUorg Nummer, oder ob diese nur optional hinzukommt.
Wenn Sie beispielsweise gezielt nach Veranstaltungen einer Person suchen, die einer anderen Organisationsnummer zugehörig ist, in den EInstellungen aber gleichzeit angegeben wurde, nur solche Veranstaltungen zu finden, die einer anderen FAUorg Nummer zugewiesen sind, dann kann es keine Treffer geben.
Ändern Sie daher im Backend unter Einstellungen -> RRZE Lectures die Einstellung unter FAUorg Nummer verwenden ab auf die Option Füge die FAUorg zur Suche nach Veranstaltungen nur dann hinzu, wenn alle anderen notwendigen Mindestangaben fehlen.
Da Abfragen nach personenbezogenen Daten stets nur in dem Maße gemacht werden, wie es unbedingt technisch notwendig ist (Prinzip der Datensparsamkeit), können bei der Suche nach der lecturer_id nur Personen gefunden werden, die eine der folgenden Personengruppen zugehören:
- Einrichtungsleiter
- Professoren und Professorinnen
- Juniorprofessoren und Juniorprofessorinnenv
- Wissenschaftliche Mitarbeiter und Mitarbeiterinnen
- Honorarprofessoren und Honorarprofessorinnen
- Privatdozenten und Privatdozentinnen
- Außerplanmäßige Professoren und Professorinnen
- Lehrbeauftragte
- Gastdozent und Gastdozentinnen
- Gastwissenschaftler und Gastwissenschaftlerinnen
Die Angabe kann, genauso wie die IdM-Kennung, bei der Person erfragt werden, deren Daten eingeblendet werden sollen. Um die eigene Identifier zu erhalten, kann wie folgt vorgegangen werden:
- Rufen Sie das IdM-Portal auf.
- Nach dem Login erscheint die Datenansicht mit den eigenen, persönlichen Daten.
- In den Daten finden Sie die Angabe eines „API-Person-Identifier“. Diese Angabe wird als Lecturer-Identifier verwendet.
Das Lectures-Plugin kann derzeit keine Daten aus vergangenen Semestern anzeigen, da das Campo-System diese Daten leider nicht bereit stellt.
Es werden nur Veranstaltungen, aus dem letzten, dem aktuellen und den anstehenden Semester gezeigt.
In der aktuellen Version des Plugins (Version 2.0.28 vom Oktober 2023) wird bei der Suche nach Veranstaltungen nur in den Datensatz der verantwortlichen Personen gesucht.
Daher werden Personen, die Einzeltermine durchführen, jedoch nicht als Verantwortliche eingetragen sind, auch nicht gefunden und somit deren Lehrveranstaltungen nicht angezeigt.
Eine Erweiterung des Plugins zur Suche und Darstellung von Lehrveranstaltungen für Dozenten, die nicht als Verantwortliche eingetragen sind, ist für eine spätere Version geplant.
Nein, die E-Mailadressen werden von uns nicht manipuliert, sondern syntaktisch korrekt dargestellt.
Dies kann auch nicht verhindert oder umgangen werden.
Hintergründe:
Uns erhalten ab und zu Anfragen, ob man Mailadressen nicht automatisch so manipulieren könnte, damit Spam-Bots diese nicht erkennen.
Beispielsweise indem man das „@„-Zeichen durch die Zeichenfolge „[ at ]“ ersetzt.
Wir setzen solche Wünsche nicht um. Aus folgenden Gründen:
- Die Umsetzung derart würde zu einer Diskriminierung von Menschen führen, die aufgrund von den individuell verwendeten Geräten oder persönlichen Einschränkungen nicht in der Lage sind, dieserart manipulierter Adressen zu erkennen und zu nutzen. So führt eine oben genannte Umsetzung dazu, dass insbesondere Menschen, die auf Vorlesesoftware angewiesen sind und sich die Seiten vorlesen lassen müssen, die Inhalte nicht als solche korrekt vorgelesen bekommen. Diese Menschen sehen sich einer unnötigen Barriere gegenüber.
Das Recht auf Barrierefreiheit ist allerdings gesetzlich festgelegt und wir als Einrichtung des Öffentlichen Dienstes sind daran gehalten.
Der subjektive Vorteil des Empfängers eine E-Mail auf ein möglicherweise geringeres Spam-Aufkommen, rechtfertigt es nicht, andere Menschen durch den Aufbau von Barrieren zu diskriminieren.
Ausnahmetatbestände greifen nicht, da es mildere und effektivere Wege zur Vermeidung von Spam gibt (siehe unten). - Zudem ist der vermeintliche Schutz nicht fachlich haltbar und ein längst Mythos:
- Adressen der gängigen Forman Vorname.Nachname@Firmendomain.de werden vom Spamer längst en Block mittels zufallserstellter Namenslisten verwendet, ohne das hierzu ein Besuch einer Webseite notwendig ist.
- Die E-Mailadresse wird an vielen weiteren Stellen verwendet, auch über diese aktuelle Website hinaus. Spätestens nach Abgabe einer Visitenkarte mit Ihrer E-Mailadresse haben Sie keine Kontrolle mehr darüber, wie sie verbreitet wird.
- Selbst wenn Spam-Bots einer auf das Sammeln von E-Mailadressen spezialisierten Firma die Webseiten besuchen, erkennen diese alle gängigen Formen der Manipulation – auch solche, die uns hier noch gar nicht eingefallen sind. Denn diese Firmen verdienen ihr Geld damit, solche Adressen zu erkennen und zu verkaufen.
Es ist ein Trugschluss zu glauben, dass man durch eine simple automatische Textmanipulation des Zeichens @ in [ at ] von den professionellen Scannern nicht erkannt wird. Die automatische Umsetzung der Adresse in die eine Richtung ist technisch genauso trivial umsetzbar, wie es die umgekehrte Richtung ist.
Ebenso sind E-Mailadressen in der Umsetzung in Form von Bildern längst kein Schutz mehr. Entsprechende Funktionen der Mustererkennung sind seit mehr als einem Jahrzehnt gängiger Stand der Technik. Spätestens mit der Entwicklung neuer KI-Verfahren sind auch sehr komplexe Manipulationen, die aus der Kombination von Bildern, Texten und dynamisch erzeugten Content bestehen, kein Problem mehr für die automatische Erkennung durch Spam-Bots.Grundsätzlich kann festgehalten werden: Jegliche automatische und manuelle Text- und Bildmanipulation kann auch automatisch wieder rückgängig gemacht werden.
- Zur Vermeidung von Spam sind allein Spam-Erkennungs- und Filterverfahren auf der Empfängerseite legitim und sinnvoll. Hierzu finden Sie hier weitere Informationen auf derInformationsseite Anti-Spam des RRZE.
Der Sprachschalter wurde bei der mobilen Darstellung bewusst, in längeren Diskussionen und aufgrund von Feedback aus der sichtbaren Anzeige genommen und in das Organisatorische Menü (nur sichtbar auf der mobilen Darstellung) getan, damit mehr Platz für das eigene Logo und den eigenen Titel bleibt.
Die Heatmaps von Inhaltsseiten in der mobilen Darstellungen auf beispielsweise www.fau.de belegen zudem, dass der Sprachschalter dort kaum verwendet wird.
Lediglich auf der Startseite wird er angeklickt. Da gleichzeitig gemessen werden kann, dass die meisten Zugriffe auf der Startseite über Suchmaschinen kommen, diese jedoch bereits nach Sprache gefiltert wurden (deutschsprachige Suchanfragen erhalten bevorzugt die deutschsprachige Website als Ergebnis, englischsprachige jedoch die englischsprachige Website), kann davon ausgegangen werden, dass die Mehrzahl aller Seitenbesucher bereits auf der jeweils gewünschten Seite sind.
Ein Sprachschalter ist aus diesem Gründen von geringerer Relevanz als die anderen Bestandteile, die im Kopfteil der Seite in der mobilen Darstellung sichtbar sein sollen.
In dem Fall, wo eine Website mehreren Departments einer Fakultät untergeordnet ist, ist zu empfehlen als Aufpunkt die Fakultät zu nehmen.
Wenn die Website mehreren Departments oder Einrichtungen verschiedener Fakultäten untergeordnet ist, würde als Aufpunkt die Uni selbst zu nehmen.
Der Ziel der Orga Breadcrumb ist der, das ein Besucher einer Website eine Vorstellung bekommt, zu welcher Organisation die Website gehört.
Dies kann aber neben dem rein organisatorischen Aspekt durchaus inhaltlich auch anderes sein.
Zum Beispiel wenn die Stellen von einem Department kommen, aber die Inhalte und Arbeiten um die es geht, einer anderen Forschungsrichtung zugeordnet werden könnten.
Überlegen Sie in diesen Fällen daher, was aus Sicht Ihrer Besucher und im Rahmen der Öffentlichkeitsarbeit nützlicher ist und entscheiden Sie pragmatisch.
Die Zugriffe auf Webangebote, die am RRZE gehostet werden, sind aus dem Netz der Universität auf statistiken.rrze.fau.de abrufbar. Die Statistik wird mittels der Software webalizer erstellt und basiert auf die anonymisierten Zugriffe auf die Webserver.
In der Statistik werden unterschiedliche Begriffe verwendet:
- „Hits“, „Anfragen“, „Gesamtabrufe“
Die Begriffe „Hits“, „Anfragen“, „Gesamtabrufe“ und deren anderssprachige Formen stehen fuer die Summe der Anfragen auf einer Domain. Sie stehen aber nicht allein für die Summe der Anfragen fuer eine Seite. Genau gibt die Zahl an, wie oft Dateien innerhalb der Domain auf dem sich die Zahl bezieht, abgerufen wurden. Diese Dateien bestehen jedoch nicht nur aus den HTML-Dateien, sondern auch aus den in diesen referenzierten Bildern, Stylesheet-Dateien und Skript-Aufrufe.
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Hits“ in einer Statistik einer Domain kann nicht durch eine andere Abrufszahl überschritten werden.
- „Seiten“, „Seitenabrufe“, „Pageviews“, „Page Impressions“
Diese Begriffe beinhalten die Zahl der Abrufe auf Dokumentseiten _exklusive_ Referenzen auf Bilder, Stylesheet-Dateien oder Skript-Abrufen. Ausserdem werden zusätzlich nur Abrufe der Seiten gezählt, wenn diese vollstaendig vom Webserver geladen wurden. (Dies bedeutet, dass Seiten, die aus einem Proxy -also einem Zwischenspeicher für Webdokumente- geladen wurden, nicht mitgezählt wurden.)
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Pageviews“, bzw. der „Seiten“ ist jedoch nur 1. Für den Fall, daß ein Proxy die Seite gespeichert hatte bei dem der Browser des Benutzers die Seite abgerufen hat, ist die Zahl der Seitenabrufe sogar nur 0.
Die Zahl der „Pageviews“ kann niemals größer als die der „Hits“ sein.
- „Dateien“, „Files“
Diese Zahl gibt an, wieviele Dateien erfolgreich von der Domain geladen wurden. Dateien sind alle Dokumente auf der Webseite, inkl. Bilder und Skripten.
Der Unterschied zur Zahl der „Anfragen“/“Hits“ besteht darin, dass hier die Abrufe, bei denen der Seiteninhalt über einen Proxy geladen wurde, nicht mitgezählt werden. D.h.: ‚Zahl der „Hits“‚ – ‚Zahl der „Dateien“‚ = ‚Zahl der Seiten, die über einen Proxy abgerufen wurden.‘ Die Zahl der „Dateien“ ist meist nur für Interesse fuer den Webmaster, da diese Einfluss auf die Größe des Datentransfers hat.Die Zahl der „Dateien“ kann niemals größer als die der „Hits“ sein. Sie ist größer als die Zahl der „Seitenabrufe“
- „Besuche“, „Sessions“, „Sitzungen“
Diese Zahl beschreibt wieviele Besucher innerhalb eines festgelegten Zeitintervals Seiten, d.h. richtige Webseiten (die Grafiken etc nicht mitgezählt), vom Webserver erfolgreich abgerufen haben. Üblicherweise wird ein Wert von 90 Sekunden für den Zeitinterval benutzt.
Die Zahl der Seitenabrufe geteilt durch die Zahl der Besucher ergibt dabei die Zahl der Seiten, die ein Besucher auf der Seite betrachtet. (Portals und Suchmaschinen werden in der Regel eine kleinere Zahl haben, als inhaltlich bezogene Seiten, die nicht sofort auf externe Angebote verweisen.)
Kurz gesagt: Je größer der Wert „Seitenabrufe“/“Besuche“ ist, je laenger bleiben die Besucher auf der Seite.Die Zahl der „Besuche“ kann niemals größer als die der „Pageviews“ sein.
- „Rechner“, „Hosts“
Diese Zahl gibt an, wieviele verschiedene Rechner innerhalb eines Zeitintervalles „Seitenabrufe“ tätigten. (Bitte beachten Sie hierbei, dass Benutzer der großen Onlinedienste meist unter einem einzigen Rechner identifiziert werden.)
Interessant ist diese Zahl dadurch, dass sie zusammen mit der Zahl der „Besuche“ eine Abschätzung zuläßt, wie oft ein spezieller Besucher zu der Seite zurückkommt, d.h. wie interessant das auch über längere Zeiträume hinweg ist.Die Zahl der „Rechner“ kann niemals größer als die der „Besuche“ sein.
Die statistische Werte halten dabei folgende Reihenfolge ein:
#“Hits“ >= #“Dateien“ >= #“Seiten“ >= #“Besuche“ >= #“Rechner“
(wobei das Zeichen ‚#‘ sich auf die Zahl bezieht.)
Unabhaengig von diesen Zahlen wird in den meisten Statistiken auch noch die Zahl der übertragenen kBytes angegeben. Diese Zahl bezieht sich in der Regel auf den Datentransfer aller Dateien innerhalb des Zeitintervals.
Der Wert #“Dateien“ / #’kBytes‘ gibt dabei die durchschnittliche Dateigröße pro Datei an.
Ja, Teile der Webstatistiken, die mit webalizer erstellt werden, können auch direkt abgerufen werden und danach mit einer geeigneten Software analysiert oder anders dargestellt werden.
Die folgenden Dateien liegen mit den entsprechenden Datumsformat (YYYY = Jahreszahl, MM = zweistellige Monatszahl, DD = zweistellige Tageszahl) jeweils in dem Statistik-Ordner des Webauftritts unter statistiken.rrze.fau.de/webauftritte/logs/Webauftritt/ .
Bitte beachten Sie, dass der Zugriff nur für Rechner aus den Netzen der Universität möglich ist.
Folgende Dateien stehen im Verzeichnis im CSV- bzw im XML-Format zur Verfügung:
- Useragents: agent_YYYYMM.tab
- Tagesdelta bei URL-Zugriffen: url_delta_YYYYMMDD.tab
- Referer: ref_YYYYMM.tab
- Suchbegriffe: search_YYYYMM.tab
- Usage: usage_YYYYMM.xml
- Site: site_YYYYMM.tab
- URL-Zugriffe: url_YYYYMM.tab
- Fehler: err_YYYYMM.tab
- Jahreszahlen: webalizer.hist
In der aktuellen Version des Plugins (Version 2.0.28 vom Oktober 2023) wird bei der Suche nach Veranstaltungen nur in den Datensatz der verantwortlichen Personen gesucht.
Daher werden Personen, die Einzeltermine durchführen, jedoch nicht als Verantwortliche eingetragen sind, auch nicht gefunden und somit deren Lehrveranstaltungen nicht angezeigt.
Eine Erweiterung des Plugins zur Suche und Darstellung von Lehrveranstaltungen für Dozenten, die nicht als Verantwortliche eingetragen sind, ist für eine spätere Version geplant.
Da Abfragen nach personenbezogenen Daten stets nur in dem Maße gemacht werden, wie es unbedingt technisch notwendig ist (Prinzip der Datensparsamkeit), können bei der Suche nach der lecturer_id nur Personen gefunden werden, die eine der folgenden Personengruppen zugehören:
- Einrichtungsleiter
- Professoren und Professorinnen
- Juniorprofessoren und Juniorprofessorinnenv
- Wissenschaftliche Mitarbeiter und Mitarbeiterinnen
- Honorarprofessoren und Honorarprofessorinnen
- Privatdozenten und Privatdozentinnen
- Außerplanmäßige Professoren und Professorinnen
- Lehrbeauftragte
- Gastdozent und Gastdozentinnen
- Gastwissenschaftler und Gastwissenschaftlerinnen
Wenn Kalendertermine aus Exchange auf der Webseite angezeigt werden, wird hierzu der ICS-Feed von Exchange verwendet.
Der ICS-Feed zeigt standardmäßig jedoch nur die Termine an, welche drei Monate in der Zukunft liegen. Alles darüber hinaus nicht.
Wenn die eingetragenen Termine entsprechend in der Zukunft liegen, können sie daher auch auf der Webseite nicht angezeigt werden.
Die Angabe kann, genauso wie die IdM-Kennung, bei der Person erfragt werden, deren Daten eingeblendet werden sollen. Um die eigene Identifier zu erhalten, kann wie folgt vorgegangen werden:
- Rufen Sie das IdM-Portal auf.
- Nach dem Login erscheint die Datenansicht mit den eigenen, persönlichen Daten.
- In den Daten finden Sie die Angabe eines „API-Person-Identifier“. Diese Angabe wird als Lecturer-Identifier verwendet.
- Navigieren Sie Einstellungen > RRZE Lectures
- Im Abschnitt „Suchen nach FAU-Org-Nr.“ suchen Sie nach Ihrer FAU Organisations-Nummer.
Ja, Teile der Webstatistiken, die mit webalizer erstellt werden, können auch direkt abgerufen werden und danach mit einer geeigneten Software analysiert oder anders dargestellt werden.
Die folgenden Dateien liegen mit den entsprechenden Datumsformat (YYYY = Jahreszahl, MM = zweistellige Monatszahl, DD = zweistellige Tageszahl) jeweils in dem Statistik-Ordner des Webauftritts unter statistiken.rrze.fau.de/webauftritte/logs/Webauftritt/ .
Bitte beachten Sie, dass der Zugriff nur für Rechner aus den Netzen der Universität möglich ist.
Folgende Dateien stehen im Verzeichnis im CSV- bzw im XML-Format zur Verfügung:
- Useragents: agent_YYYYMM.tab
- Tagesdelta bei URL-Zugriffen: url_delta_YYYYMMDD.tab
- Referer: ref_YYYYMM.tab
- Suchbegriffe: search_YYYYMM.tab
- Usage: usage_YYYYMM.xml
- Site: site_YYYYMM.tab
- URL-Zugriffe: url_YYYYMM.tab
- Fehler: err_YYYYMM.tab
- Jahreszahlen: webalizer.hist
Sie sollten, sowohl für Besucherinnen und Besucher Ihrer Homepage, aber auch für Google, ausreichend Content bereitstellen, bevor Sie Ihre Seite veröffentlichen. Falls das nicht der Fall ist, stellen Sie keinen relevanten Inhalt für Suchmaschinen dar, und Ihre Seite wird im Ranking schlechter abschneiden und auch weniger oft gecrawlt.
Vorab: Es ist zwar möglich, bei Google zu beantragen, dass eine bestimmte Seite aus dem Index genommen wird, sodass diese Seite nicht mehr in den Suchergebnissen auftaucht. Sollte man sich dann aber irgendwann dazu entscheiden, die Seite doch wieder indexieren zu lassen, kann das längere Zeit in Anspruch nehmen. Wir raten von diesem Vorgehen ab.
Wer dennoch diese Option wählen und bei Google die Indexierung der Seite rückgängig machen möchte, muss sich bei Google Search Console anmelden und dort bei der betreffenden Seite den Punkt „entfernen“ anwählen. (Hier gibt es weitere Informationen zum Ausschließen von Inhalten in der Google-Suche.)
Auch von sogenannten „Baustellen-Seiten“, auf denen der User dann nur so etwas sieht wie „An dieser Seite wird gerade gearbeitet“, raten wir ab, da diese sich negativ auf das Google-Ranking auswirken.
Eine bessere Lösung, wenn man nicht möchte, dass ein bereits publizierter Inhalt von Nutzerinnen und Nutzern gesehen wird, ist, die Seite innerhalb der Homepage an einen Ort zu verschieben, an dem sie nicht gefunden wird. Dazu können Sie die Seite, die nicht gefunden werden soll, einem Menüpunkt zuordnen, der nicht öffentlich sichtbar ist. Suchmaschinen können die Seite dann zwar immer noch anzeigen, aber Userinnen und User finden sie nicht mehr (so leicht).
Eine andere Möglichkeit ist, die einzelne Seite, von der man nicht möchte, dass sie von anderen gelesen wird, mit einem Passwort zu schützen.
Das ist kein relevanter Inhalt für Suchmaschinen. Nur eigener, entsprechend aufbereiteter Content wird dazu führen, dass Ihre Webseite gut bei Google aufgefunden wird.
Zunächst einmal sollten Sie überprüfen, ob Ihre Seite bei Google schlecht rankt oder ob sie von Google noch nicht indexiert worden ist und deshalb noch nicht in den Sucherergebnissen auftaucht. Dazu rufen Sie Google auf und geben in das Suchfenster ein: „site:die URL Ihrer Homepage“. Beim RRZE wäre das dann zum Beispiel: site:www.rrze.fau.de. Mit dieser Sucheingabe zeigt Google alle Ihrer bislang indexierten Seiten auf.
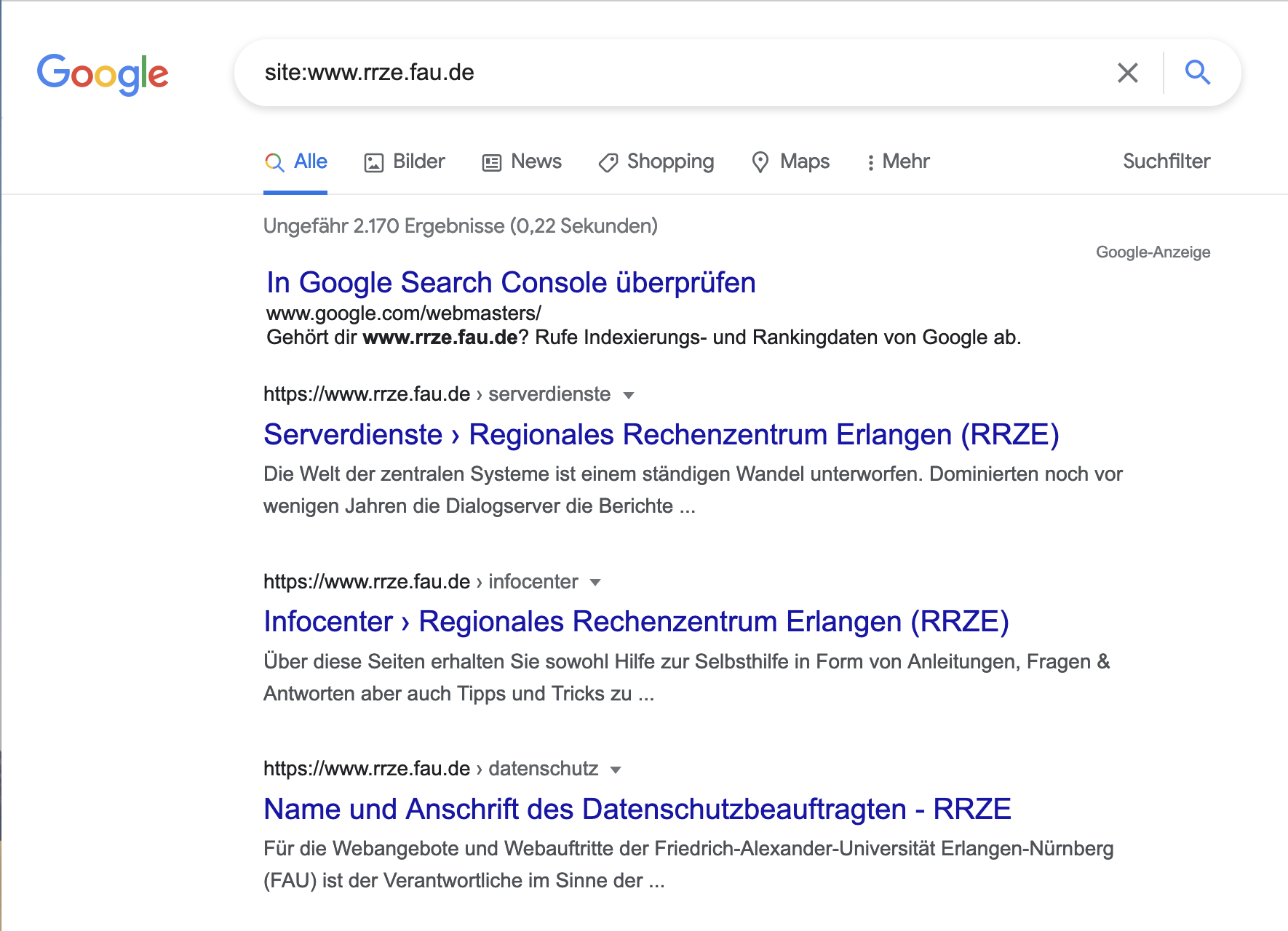
Nun sehen Sie entweder, dass Google Ihre Seite / Ihren Beitrag indexiert hat – in diesem Fall gilt es, die Seite / den Beitrag zu optimieren, um Ihr Ranking zu verbessern und von Google besser aufgefunden zu werden.
Oder Sie stellen fest, dass Google Ihre Seite / Ihren Beitrag wirklich noch nicht indexiert hat. Das kann mehrere Ursachen haben.
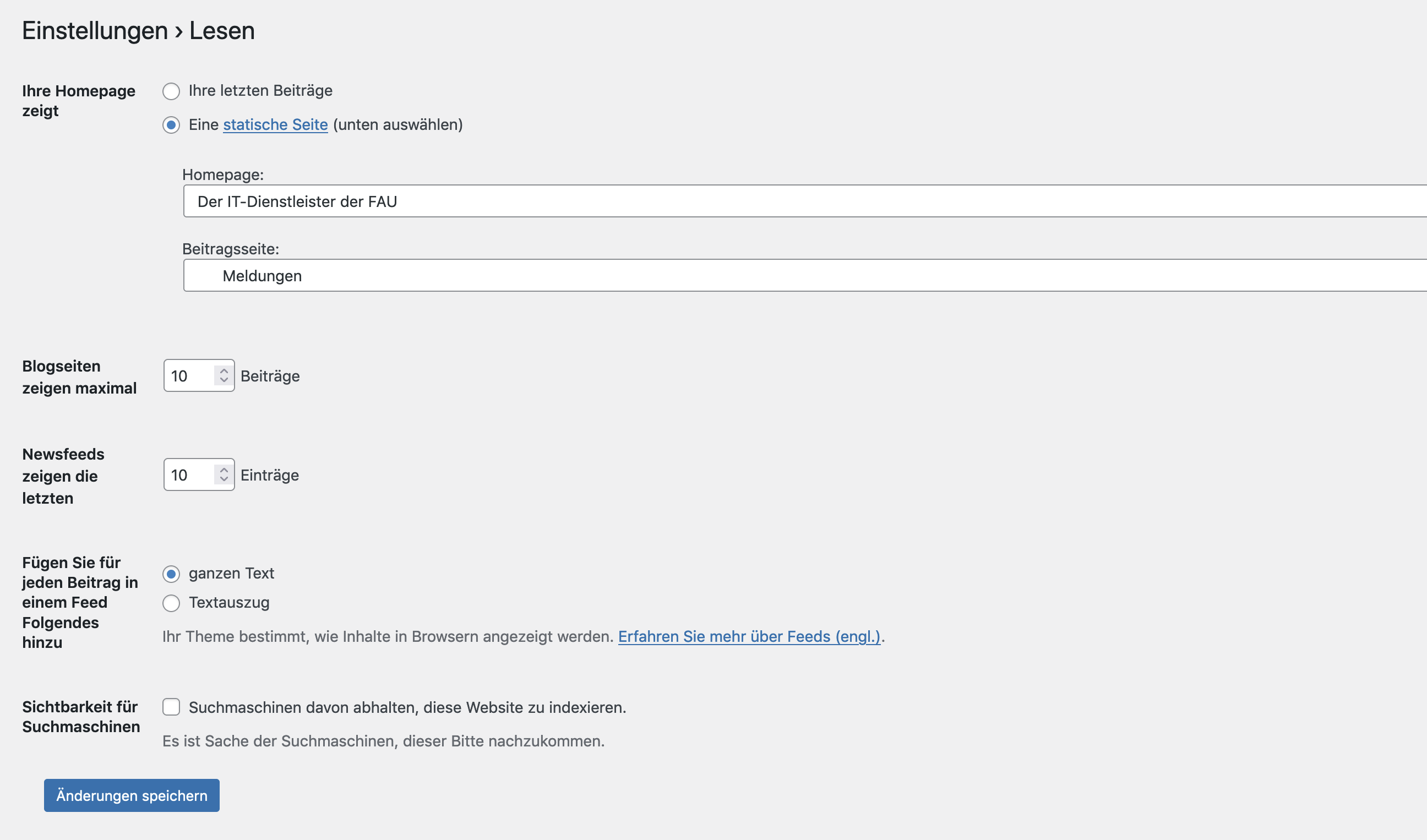
- Wenn Ihre gesamte Seite von Google noch nicht indexiert worden ist, können Sie einmal im WordPress-Backend nachsehen, ob ein Haken bei „Suchmaschinen davon abhalten, diese Website zu indexieren“ (zu finden unter „Einstellung“ – „Lesen“ – „Sichtbarkeit für Suchmaschinen“) gesetzt worden ist. Das ist aber eher unwahrscheinlich, weil dies keine Standardeinstellung ist und Sie den Haken also selbst gesetzt haben müssen.
- Es könnte auch sein, dass das CMS-Plugin PrivateSite (falls Sie dieses verwendet haben) den Zugriff für Google-Crawler verhindert. In diesem Fall müssen Sie dieses wieder deaktivieren, damit die Seite durch Google indexiert werden kann.
- Sie sollten sich außerdem in Ihr Konto bei Google Search Console einloggen (bzw. sich dort registrieren lassen, falls noch kein Konto besteht). Dort können Sie Google um ein Crawling Ihrer Seite bitten, sodass neue Seiten schneller in den Suchergebnissen erscheinen. Falls es Probleme mit dem Crawling geben sollte, wird Ihnen das die Google Search Console rückmelden und Vorschläge zu deren Lösung machen. Siehe auch: „Wie beschleunige ich die Indexierung meiner Seite?“
Generell empfehlen wir, die Sprache einer Seite einheitlich zu halten und diese in Übereinstimmung mit der Domain-Endung zu wählen. Wenn die Domain z. B. auf „de“ endet, sollte die Sprache der Webseite Deutsch sein. Außerdem sollte im WordPress-Backend unter „Einstellungen“ – „Allgemein“ – „Sprache der Webseite“ die jeweils passende Sprache festgelegt sein.
Die einheitliche Sprachwahl gilt auch für angegliederte PDFs. Sollten diese englisch sein, die Hauptsprache der Webseite aber Deutsch, kann Google den Content nicht mehr gut zuordnen. Auch die Barrierefreiheit der Seite leidet darunter, denn Screenreader werden versuchen, den englischen Inhalt auf Deutsch vorzulesen. Falls Sie eine deutsche und englische Version anbieten möchten, können Sie Ihre Seite mit dem Plugin RRZE Multilang übersetzen.
Es gibt sehr viele Faktoren, die das Ranking beeinflussen.
Grundsätzlich sollten folgende Punkte für ein gutes Ranking umgesetzt sein:
- Ihre Seite sollte genügend relevante Inhalte enthalten, die für Userinnen und User, aber auch für Google interessant sind. Stichwort: eigener, gut aufbereiteter, nicht zu kurzer Content. (Hier finden Sie Tipps dazu, wie guter Content gestaltet sein sollte.)
- Ihre Seite sollte übersichtlich strukturiert sein. Das bedeutet: viele aussagekräftige Zwischenüberschriften nutzen, die das Hauptkeyword enthalten, zu lange Textblöcke vermeiden und stattdessen lieber mehr Absätze machen; nach Möglichkeit auch Bebilderung des Themas einbauen.
- Die Sprache der Homepage sollte richtig festgelegt werden. Uns erreichen oft Anfragen von Nutzerinnen und Nutzern, deren Seiten schlecht von Google gefunden werden, und die zum Teil deutschen, zum Teil englischen Content haben, das aber für Suchmaschinen nicht ausreichend markiert haben. Die Folge: Die Suchmaschinen können den Content nicht gut zuordnen, die Barrierefreiheit leidet (da auch Screenreader die Sprache nicht richtig einordnen können), das Ranking wird schlechter.
- Die Keywords, also der Hauptschlagworte, anhand derer der Beitrag oder die Seite gefunden werden soll, sollten sowohl in der h1- als auch in den h2-Überschriften vorkommen – sowie auch in der URL!
- Das automatisch auf unserem WordPress laufende Plugin wpSEO sollte genutzt werden, z. B. um passende Meta-Beschreibungen für Google zu entwerfen.
- Linkziele sollten ausreichend deklariert werden. Sie sollten eine Phrase verwenden, die unverkennbar den gewünschten Inhalt beschreibt. Zum Beispiel: „Tagungsprogramm 2021“ anstatt „Zum Programm geht es hier.“
- Leere Content-Seiten sollten vermieden werden. Leere Seiten signalisieren Suchmaschinen, dass die entsprechende Seite wenig Mehrwert für Seitenbesucherinnen und -besucher bietet. Deshalb fallen diese in der Regel entweder ganz aus dem Google-Ranking hinaus oder im Ranking ab.
Zur Verifikation der Website als Property in den Google Webmaster Tools wird die Methode über den HTML-Tag ausgewählt. Google erstellt dann auf der Einrichtungsseite eine HTML-Anweisung. Von dieser Anweisung kopiert man den Bestandteil, der im Attribut „content“ angegeben ist.
Bei einer Website, die eines der FAU Themes nutzt, finden Sie im Customizer unter „Erweitert“ >> Metadaten und Inhalte ein Eingabefeld, in dem Sie diesen Content einfügen.
Nachdem Sie dies getan und gespeichert haben, lassen Sie Google die Website prüfen.
Google wird damit erkennen, dass Sie die Berechtigungen an der Website haben und Ihnen die Website zuordnen.
Sie rufen Google auf und geben in das Suchfenster ein: „site:die URL Ihrer Homepage“. Beim RRZE wäre das dann zum Beispiel: site:www.rrze.fau.de. Mit dieser Sucheingabe zeigt Google alle Ihrer bislang indexierten Seiten auf.
Die Zugriffe auf Webangebote, die am RRZE gehostet werden, sind aus dem Netz der Universität auf statistiken.rrze.fau.de abrufbar. Die Statistik wird mittels der Software webalizer erstellt und basiert auf die anonymisierten Zugriffe auf die Webserver.
In der Statistik werden unterschiedliche Begriffe verwendet:
- „Hits“, „Anfragen“, „Gesamtabrufe“
Die Begriffe „Hits“, „Anfragen“, „Gesamtabrufe“ und deren anderssprachige Formen stehen fuer die Summe der Anfragen auf einer Domain. Sie stehen aber nicht allein für die Summe der Anfragen fuer eine Seite. Genau gibt die Zahl an, wie oft Dateien innerhalb der Domain auf dem sich die Zahl bezieht, abgerufen wurden. Diese Dateien bestehen jedoch nicht nur aus den HTML-Dateien, sondern auch aus den in diesen referenzierten Bildern, Stylesheet-Dateien und Skript-Aufrufe.
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Hits“ in einer Statistik einer Domain kann nicht durch eine andere Abrufszahl überschritten werden.
- „Seiten“, „Seitenabrufe“, „Pageviews“, „Page Impressions“
Diese Begriffe beinhalten die Zahl der Abrufe auf Dokumentseiten _exklusive_ Referenzen auf Bilder, Stylesheet-Dateien oder Skript-Abrufen. Ausserdem werden zusätzlich nur Abrufe der Seiten gezählt, wenn diese vollstaendig vom Webserver geladen wurden. (Dies bedeutet, dass Seiten, die aus einem Proxy -also einem Zwischenspeicher für Webdokumente- geladen wurden, nicht mitgezählt wurden.)
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Pageviews“, bzw. der „Seiten“ ist jedoch nur 1. Für den Fall, daß ein Proxy die Seite gespeichert hatte bei dem der Browser des Benutzers die Seite abgerufen hat, ist die Zahl der Seitenabrufe sogar nur 0.
Die Zahl der „Pageviews“ kann niemals größer als die der „Hits“ sein.
- „Dateien“, „Files“
Diese Zahl gibt an, wieviele Dateien erfolgreich von der Domain geladen wurden. Dateien sind alle Dokumente auf der Webseite, inkl. Bilder und Skripten.
Der Unterschied zur Zahl der „Anfragen“/“Hits“ besteht darin, dass hier die Abrufe, bei denen der Seiteninhalt über einen Proxy geladen wurde, nicht mitgezählt werden. D.h.: ‚Zahl der „Hits“‚ – ‚Zahl der „Dateien“‚ = ‚Zahl der Seiten, die über einen Proxy abgerufen wurden.‘ Die Zahl der „Dateien“ ist meist nur für Interesse fuer den Webmaster, da diese Einfluss auf die Größe des Datentransfers hat.Die Zahl der „Dateien“ kann niemals größer als die der „Hits“ sein. Sie ist größer als die Zahl der „Seitenabrufe“
- „Besuche“, „Sessions“, „Sitzungen“
Diese Zahl beschreibt wieviele Besucher innerhalb eines festgelegten Zeitintervals Seiten, d.h. richtige Webseiten (die Grafiken etc nicht mitgezählt), vom Webserver erfolgreich abgerufen haben. Üblicherweise wird ein Wert von 90 Sekunden für den Zeitinterval benutzt.
Die Zahl der Seitenabrufe geteilt durch die Zahl der Besucher ergibt dabei die Zahl der Seiten, die ein Besucher auf der Seite betrachtet. (Portals und Suchmaschinen werden in der Regel eine kleinere Zahl haben, als inhaltlich bezogene Seiten, die nicht sofort auf externe Angebote verweisen.)
Kurz gesagt: Je größer der Wert „Seitenabrufe“/“Besuche“ ist, je laenger bleiben die Besucher auf der Seite.Die Zahl der „Besuche“ kann niemals größer als die der „Pageviews“ sein.
- „Rechner“, „Hosts“
Diese Zahl gibt an, wieviele verschiedene Rechner innerhalb eines Zeitintervalles „Seitenabrufe“ tätigten. (Bitte beachten Sie hierbei, dass Benutzer der großen Onlinedienste meist unter einem einzigen Rechner identifiziert werden.)
Interessant ist diese Zahl dadurch, dass sie zusammen mit der Zahl der „Besuche“ eine Abschätzung zuläßt, wie oft ein spezieller Besucher zu der Seite zurückkommt, d.h. wie interessant das auch über längere Zeiträume hinweg ist.Die Zahl der „Rechner“ kann niemals größer als die der „Besuche“ sein.
Die statistische Werte halten dabei folgende Reihenfolge ein:
#“Hits“ >= #“Dateien“ >= #“Seiten“ >= #“Besuche“ >= #“Rechner“
(wobei das Zeichen ‚#‘ sich auf die Zahl bezieht.)
Unabhaengig von diesen Zahlen wird in den meisten Statistiken auch noch die Zahl der übertragenen kBytes angegeben. Diese Zahl bezieht sich in der Regel auf den Datentransfer aller Dateien innerhalb des Zeitintervals.
Der Wert #“Dateien“ / #’kBytes‘ gibt dabei die durchschnittliche Dateigröße pro Datei an.
Nein, die E-Mailadressen werden von uns nicht manipuliert, sondern syntaktisch korrekt dargestellt.
Dies kann auch nicht verhindert oder umgangen werden.
Hintergründe:
Uns erhalten ab und zu Anfragen, ob man Mailadressen nicht automatisch so manipulieren könnte, damit Spam-Bots diese nicht erkennen.
Beispielsweise indem man das „@„-Zeichen durch die Zeichenfolge „[ at ]“ ersetzt.
Wir setzen solche Wünsche nicht um. Aus folgenden Gründen:
- Die Umsetzung derart würde zu einer Diskriminierung von Menschen führen, die aufgrund von den individuell verwendeten Geräten oder persönlichen Einschränkungen nicht in der Lage sind, dieserart manipulierter Adressen zu erkennen und zu nutzen. So führt eine oben genannte Umsetzung dazu, dass insbesondere Menschen, die auf Vorlesesoftware angewiesen sind und sich die Seiten vorlesen lassen müssen, die Inhalte nicht als solche korrekt vorgelesen bekommen. Diese Menschen sehen sich einer unnötigen Barriere gegenüber.
Das Recht auf Barrierefreiheit ist allerdings gesetzlich festgelegt und wir als Einrichtung des Öffentlichen Dienstes sind daran gehalten.
Der subjektive Vorteil des Empfängers eine E-Mail auf ein möglicherweise geringeres Spam-Aufkommen, rechtfertigt es nicht, andere Menschen durch den Aufbau von Barrieren zu diskriminieren.
Ausnahmetatbestände greifen nicht, da es mildere und effektivere Wege zur Vermeidung von Spam gibt (siehe unten). - Zudem ist der vermeintliche Schutz nicht fachlich haltbar und ein längst Mythos:
- Adressen der gängigen Forman Vorname.Nachname@Firmendomain.de werden vom Spamer längst en Block mittels zufallserstellter Namenslisten verwendet, ohne das hierzu ein Besuch einer Webseite notwendig ist.
- Die E-Mailadresse wird an vielen weiteren Stellen verwendet, auch über diese aktuelle Website hinaus. Spätestens nach Abgabe einer Visitenkarte mit Ihrer E-Mailadresse haben Sie keine Kontrolle mehr darüber, wie sie verbreitet wird.
- Selbst wenn Spam-Bots einer auf das Sammeln von E-Mailadressen spezialisierten Firma die Webseiten besuchen, erkennen diese alle gängigen Formen der Manipulation – auch solche, die uns hier noch gar nicht eingefallen sind. Denn diese Firmen verdienen ihr Geld damit, solche Adressen zu erkennen und zu verkaufen.
Es ist ein Trugschluss zu glauben, dass man durch eine simple automatische Textmanipulation des Zeichens @ in [ at ] von den professionellen Scannern nicht erkannt wird. Die automatische Umsetzung der Adresse in die eine Richtung ist technisch genauso trivial umsetzbar, wie es die umgekehrte Richtung ist.
Ebenso sind E-Mailadressen in der Umsetzung in Form von Bildern längst kein Schutz mehr. Entsprechende Funktionen der Mustererkennung sind seit mehr als einem Jahrzehnt gängiger Stand der Technik. Spätestens mit der Entwicklung neuer KI-Verfahren sind auch sehr komplexe Manipulationen, die aus der Kombination von Bildern, Texten und dynamisch erzeugten Content bestehen, kein Problem mehr für die automatische Erkennung durch Spam-Bots.Grundsätzlich kann festgehalten werden: Jegliche automatische und manuelle Text- und Bildmanipulation kann auch automatisch wieder rückgängig gemacht werden.
- Zur Vermeidung von Spam sind allein Spam-Erkennungs- und Filterverfahren auf der Empfängerseite legitim und sinnvoll. Hierzu finden Sie hier weitere Informationen auf derInformationsseite Anti-Spam des RRZE.
Der Sprachschalter wurde bei der mobilen Darstellung bewusst, in längeren Diskussionen und aufgrund von Feedback aus der sichtbaren Anzeige genommen und in das Organisatorische Menü (nur sichtbar auf der mobilen Darstellung) getan, damit mehr Platz für das eigene Logo und den eigenen Titel bleibt.
Die Heatmaps von Inhaltsseiten in der mobilen Darstellungen auf beispielsweise www.fau.de belegen zudem, dass der Sprachschalter dort kaum verwendet wird.
Lediglich auf der Startseite wird er angeklickt. Da gleichzeitig gemessen werden kann, dass die meisten Zugriffe auf der Startseite über Suchmaschinen kommen, diese jedoch bereits nach Sprache gefiltert wurden (deutschsprachige Suchanfragen erhalten bevorzugt die deutschsprachige Website als Ergebnis, englischsprachige jedoch die englischsprachige Website), kann davon ausgegangen werden, dass die Mehrzahl aller Seitenbesucher bereits auf der jeweils gewünschten Seite sind.
Ein Sprachschalter ist aus diesem Gründen von geringerer Relevanz als die anderen Bestandteile, die im Kopfteil der Seite in der mobilen Darstellung sichtbar sein sollen.
Ja, Teile der Webstatistiken, die mit webalizer erstellt werden, können auch direkt abgerufen werden und danach mit einer geeigneten Software analysiert oder anders dargestellt werden.
Die folgenden Dateien liegen mit den entsprechenden Datumsformat (YYYY = Jahreszahl, MM = zweistellige Monatszahl, DD = zweistellige Tageszahl) jeweils in dem Statistik-Ordner des Webauftritts unter statistiken.rrze.fau.de/webauftritte/logs/Webauftritt/ .
Bitte beachten Sie, dass der Zugriff nur für Rechner aus den Netzen der Universität möglich ist.
Folgende Dateien stehen im Verzeichnis im CSV- bzw im XML-Format zur Verfügung:
- Useragents: agent_YYYYMM.tab
- Tagesdelta bei URL-Zugriffen: url_delta_YYYYMMDD.tab
- Referer: ref_YYYYMM.tab
- Suchbegriffe: search_YYYYMM.tab
- Usage: usage_YYYYMM.xml
- Site: site_YYYYMM.tab
- URL-Zugriffe: url_YYYYMM.tab
- Fehler: err_YYYYMM.tab
- Jahreszahlen: webalizer.hist
Bitte prüfen Sie die Konfiguration des Plugins im Backend hinsichtlich der Nutzung der eigenen FAUorg Nummer.
Ab der Version 2.0.28 wird in den Einstellungen festgelegt, ob die Suche nach Lehrveranstaltungen stets ergänzt wird um eine Filterung nach einer FAUorg Nummer, oder ob diese nur optional hinzukommt.
Wenn Sie beispielsweise gezielt nach Veranstaltungen einer Person suchen, die einer anderen Organisationsnummer zugehörig ist, in den EInstellungen aber gleichzeit angegeben wurde, nur solche Veranstaltungen zu finden, die einer anderen FAUorg Nummer zugewiesen sind, dann kann es keine Treffer geben.
Ändern Sie daher im Backend unter Einstellungen -> RRZE Lectures die Einstellung unter FAUorg Nummer verwenden ab auf die Option Füge die FAUorg zur Suche nach Veranstaltungen nur dann hinzu, wenn alle anderen notwendigen Mindestangaben fehlen.
Ja, Teile der Webstatistiken, die mit webalizer erstellt werden, können auch direkt abgerufen werden und danach mit einer geeigneten Software analysiert oder anders dargestellt werden.
Die folgenden Dateien liegen mit den entsprechenden Datumsformat (YYYY = Jahreszahl, MM = zweistellige Monatszahl, DD = zweistellige Tageszahl) jeweils in dem Statistik-Ordner des Webauftritts unter statistiken.rrze.fau.de/webauftritte/logs/Webauftritt/ .
Bitte beachten Sie, dass der Zugriff nur für Rechner aus den Netzen der Universität möglich ist.
Folgende Dateien stehen im Verzeichnis im CSV- bzw im XML-Format zur Verfügung:
- Useragents: agent_YYYYMM.tab
- Tagesdelta bei URL-Zugriffen: url_delta_YYYYMMDD.tab
- Referer: ref_YYYYMM.tab
- Suchbegriffe: search_YYYYMM.tab
- Usage: usage_YYYYMM.xml
- Site: site_YYYYMM.tab
- URL-Zugriffe: url_YYYYMM.tab
- Fehler: err_YYYYMM.tab
- Jahreszahlen: webalizer.hist
Grund: Das Bild wurde wahrscheinlich vor 2020 hochgeladen. Damals wurden beim Upload nur kleine Bildformate erstellt. Die in den neuen Versionen des Themes nach 2020 gebräuchlichen Bildformate fehlen jedoch. Lösung: Laden Sie ein neues Bild der Person hoch. Vielleicht wäre dies ja auch nach der langen Zeit eine Gelegenheit, alte Bilder zu ersetzen.
Das Lectures-Plugin kann derzeit keine Daten aus vergangenen Semestern anzeigen, da das Campo-System diese Daten leider nicht bereit stellt.
Es werden nur Veranstaltungen, aus dem letzten, dem aktuellen und den anstehenden Semester gezeigt.
Die Zugriffe auf Webangebote, die am RRZE gehostet werden, sind aus dem Netz der Universität auf statistiken.rrze.fau.de abrufbar. Die Statistik wird mittels der Software webalizer erstellt und basiert auf die anonymisierten Zugriffe auf die Webserver.
In der Statistik werden unterschiedliche Begriffe verwendet:
- „Hits“, „Anfragen“, „Gesamtabrufe“
Die Begriffe „Hits“, „Anfragen“, „Gesamtabrufe“ und deren anderssprachige Formen stehen fuer die Summe der Anfragen auf einer Domain. Sie stehen aber nicht allein für die Summe der Anfragen fuer eine Seite. Genau gibt die Zahl an, wie oft Dateien innerhalb der Domain auf dem sich die Zahl bezieht, abgerufen wurden. Diese Dateien bestehen jedoch nicht nur aus den HTML-Dateien, sondern auch aus den in diesen referenzierten Bildern, Stylesheet-Dateien und Skript-Aufrufe.
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Hits“ in einer Statistik einer Domain kann nicht durch eine andere Abrufszahl überschritten werden.
- „Seiten“, „Seitenabrufe“, „Pageviews“, „Page Impressions“
Diese Begriffe beinhalten die Zahl der Abrufe auf Dokumentseiten _exklusive_ Referenzen auf Bilder, Stylesheet-Dateien oder Skript-Abrufen. Ausserdem werden zusätzlich nur Abrufe der Seiten gezählt, wenn diese vollstaendig vom Webserver geladen wurden. (Dies bedeutet, dass Seiten, die aus einem Proxy -also einem Zwischenspeicher für Webdokumente- geladen wurden, nicht mitgezählt wurden.)
Beispiel: Die Seite index.html enthält 3 Bilder und eine Referenz auf eine Stylesheet-Datei. Wird diese Seite aufgerufen werden in der Logdatei 5 Hits vermerkt:1 Hit fuer die Datei index.html
3 Hits fuer jeweils ein Bild
1 Hit fuer die Stylesheet-DateiDie Zahl der „Pageviews“, bzw. der „Seiten“ ist jedoch nur 1. Für den Fall, daß ein Proxy die Seite gespeichert hatte bei dem der Browser des Benutzers die Seite abgerufen hat, ist die Zahl der Seitenabrufe sogar nur 0.
Die Zahl der „Pageviews“ kann niemals größer als die der „Hits“ sein.
- „Dateien“, „Files“
Diese Zahl gibt an, wieviele Dateien erfolgreich von der Domain geladen wurden. Dateien sind alle Dokumente auf der Webseite, inkl. Bilder und Skripten.
Der Unterschied zur Zahl der „Anfragen“/“Hits“ besteht darin, dass hier die Abrufe, bei denen der Seiteninhalt über einen Proxy geladen wurde, nicht mitgezählt werden. D.h.: ‚Zahl der „Hits“‚ – ‚Zahl der „Dateien“‚ = ‚Zahl der Seiten, die über einen Proxy abgerufen wurden.‘ Die Zahl der „Dateien“ ist meist nur für Interesse fuer den Webmaster, da diese Einfluss auf die Größe des Datentransfers hat.Die Zahl der „Dateien“ kann niemals größer als die der „Hits“ sein. Sie ist größer als die Zahl der „Seitenabrufe“
- „Besuche“, „Sessions“, „Sitzungen“
Diese Zahl beschreibt wieviele Besucher innerhalb eines festgelegten Zeitintervals Seiten, d.h. richtige Webseiten (die Grafiken etc nicht mitgezählt), vom Webserver erfolgreich abgerufen haben. Üblicherweise wird ein Wert von 90 Sekunden für den Zeitinterval benutzt.
Die Zahl der Seitenabrufe geteilt durch die Zahl der Besucher ergibt dabei die Zahl der Seiten, die ein Besucher auf der Seite betrachtet. (Portals und Suchmaschinen werden in der Regel eine kleinere Zahl haben, als inhaltlich bezogene Seiten, die nicht sofort auf externe Angebote verweisen.)
Kurz gesagt: Je größer der Wert „Seitenabrufe“/“Besuche“ ist, je laenger bleiben die Besucher auf der Seite.Die Zahl der „Besuche“ kann niemals größer als die der „Pageviews“ sein.
- „Rechner“, „Hosts“
Diese Zahl gibt an, wieviele verschiedene Rechner innerhalb eines Zeitintervalles „Seitenabrufe“ tätigten. (Bitte beachten Sie hierbei, dass Benutzer der großen Onlinedienste meist unter einem einzigen Rechner identifiziert werden.)
Interessant ist diese Zahl dadurch, dass sie zusammen mit der Zahl der „Besuche“ eine Abschätzung zuläßt, wie oft ein spezieller Besucher zu der Seite zurückkommt, d.h. wie interessant das auch über längere Zeiträume hinweg ist.Die Zahl der „Rechner“ kann niemals größer als die der „Besuche“ sein.
Die statistische Werte halten dabei folgende Reihenfolge ein:
#“Hits“ >= #“Dateien“ >= #“Seiten“ >= #“Besuche“ >= #“Rechner“
(wobei das Zeichen ‚#‘ sich auf die Zahl bezieht.)
Unabhaengig von diesen Zahlen wird in den meisten Statistiken auch noch die Zahl der übertragenen kBytes angegeben. Diese Zahl bezieht sich in der Regel auf den Datentransfer aller Dateien innerhalb des Zeitintervals.
Der Wert #“Dateien“ / #’kBytes‘ gibt dabei die durchschnittliche Dateigröße pro Datei an.
Ja, Teile der Webstatistiken, die mit webalizer erstellt werden, können auch direkt abgerufen werden und danach mit einer geeigneten Software analysiert oder anders dargestellt werden.
Die folgenden Dateien liegen mit den entsprechenden Datumsformat (YYYY = Jahreszahl, MM = zweistellige Monatszahl, DD = zweistellige Tageszahl) jeweils in dem Statistik-Ordner des Webauftritts unter statistiken.rrze.fau.de/webauftritte/logs/Webauftritt/ .
Bitte beachten Sie, dass der Zugriff nur für Rechner aus den Netzen der Universität möglich ist.
Folgende Dateien stehen im Verzeichnis im CSV- bzw im XML-Format zur Verfügung:
- Useragents: agent_YYYYMM.tab
- Tagesdelta bei URL-Zugriffen: url_delta_YYYYMMDD.tab
- Referer: ref_YYYYMM.tab
- Suchbegriffe: search_YYYYMM.tab
- Usage: usage_YYYYMM.xml
- Site: site_YYYYMM.tab
- URL-Zugriffe: url_YYYYMM.tab
- Fehler: err_YYYYMM.tab
- Jahreszahlen: webalizer.hist
Ja, Teile der Webstatistiken, die mit webalizer erstellt werden, können auch direkt abgerufen werden und danach mit einer geeigneten Software analysiert oder anders dargestellt werden.
Die folgenden Dateien liegen mit den entsprechenden Datumsformat (YYYY = Jahreszahl, MM = zweistellige Monatszahl, DD = zweistellige Tageszahl) jeweils in dem Statistik-Ordner des Webauftritts unter statistiken.rrze.fau.de/webauftritte/logs/Webauftritt/ .
Bitte beachten Sie, dass der Zugriff nur für Rechner aus den Netzen der Universität möglich ist.
Folgende Dateien stehen im Verzeichnis im CSV- bzw im XML-Format zur Verfügung:
- Useragents: agent_YYYYMM.tab
- Tagesdelta bei URL-Zugriffen: url_delta_YYYYMMDD.tab
- Referer: ref_YYYYMM.tab
- Suchbegriffe: search_YYYYMM.tab
- Usage: usage_YYYYMM.xml
- Site: site_YYYYMM.tab
- URL-Zugriffe: url_YYYYMM.tab
- Fehler: err_YYYYMM.tab
- Jahreszahlen: webalizer.hist
Ja, Teile der Webstatistiken, die mit webalizer erstellt werden, können auch direkt abgerufen werden und danach mit einer geeigneten Software analysiert oder anders dargestellt werden.
Die folgenden Dateien liegen mit den entsprechenden Datumsformat (YYYY = Jahreszahl, MM = zweistellige Monatszahl, DD = zweistellige Tageszahl) jeweils in dem Statistik-Ordner des Webauftritts unter statistiken.rrze.fau.de/webauftritte/logs/Webauftritt/ .
Bitte beachten Sie, dass der Zugriff nur für Rechner aus den Netzen der Universität möglich ist.
Folgende Dateien stehen im Verzeichnis im CSV- bzw im XML-Format zur Verfügung:
- Useragents: agent_YYYYMM.tab
- Tagesdelta bei URL-Zugriffen: url_delta_YYYYMMDD.tab
- Referer: ref_YYYYMM.tab
- Suchbegriffe: search_YYYYMM.tab
- Usage: usage_YYYYMM.xml
- Site: site_YYYYMM.tab
- URL-Zugriffe: url_YYYYMM.tab
- Fehler: err_YYYYMM.tab
- Jahreszahlen: webalizer.hist
Ja, Teile der Webstatistiken, die mit webalizer erstellt werden, können auch direkt abgerufen werden und danach mit einer geeigneten Software analysiert oder anders dargestellt werden.
Die folgenden Dateien liegen mit den entsprechenden Datumsformat (YYYY = Jahreszahl, MM = zweistellige Monatszahl, DD = zweistellige Tageszahl) jeweils in dem Statistik-Ordner des Webauftritts unter statistiken.rrze.fau.de/webauftritte/logs/Webauftritt/ .
Bitte beachten Sie, dass der Zugriff nur für Rechner aus den Netzen der Universität möglich ist.
Folgende Dateien stehen im Verzeichnis im CSV- bzw im XML-Format zur Verfügung:
- Useragents: agent_YYYYMM.tab
- Tagesdelta bei URL-Zugriffen: url_delta_YYYYMMDD.tab
- Referer: ref_YYYYMM.tab
- Suchbegriffe: search_YYYYMM.tab
- Usage: usage_YYYYMM.xml
- Site: site_YYYYMM.tab
- URL-Zugriffe: url_YYYYMM.tab
- Fehler: err_YYYYMM.tab
- Jahreszahlen: webalizer.hist
Code
[faq glossary="tag tabs"]